Duplicate Data Elephant in the Room?
Smartly managed data replication is an important element of many enterprises’ IT operations. Good. The problematic distant cousin to this is data duplication. A sloppy, hard-to-avoid problem. Data deduplication (DD) solves this problem by eliminating redundant data and reducing storage requirements—also known as "intelligent compression" or "single-instance storage". Data deduplication can reduce the amount of data stored on media considerably, as well as improve data protection and increase the speed of service.
Historically DD was a feature of appliances such as VTLs and WAN optimizers. Fortunately for many companies that cannot or do not want to afford the costs of these appliances, DD is now being incorporated into backups applications.
Some key, specific benefits of DD include:
Companies can see benefits in lower storage space requirements that will save money on storage budgets.
In terms of storage space alone, we’ve seen up to 90% disk space savings.
The more efficient use of disk space also allows for longer disk retention periods, which provides better recovery time objectives (RTO) for a longer time and reduces the need for tape backups.
Data deduplication also reduces the data that must be sent across a WAN for remote backups, replication, and disaster recovery.
Reductions in power, space and cooling requirements are also a benefit of DD.
Within the virtual environment the ability to deduplicate VMDK files is a big benefit.
The major vendors have DD capabilities, including EMC, Symantec, IBM, CommVault, Quantum and the like. Check it out.
Related Blog Posts

AI, Data & Storage, Education, Market Intelligence, Students Around The World, Technology
The 2026 FETC Conference took place in Orlando, Florida this year, where K-12 education leaders highlighted how budgets, technology trends, requirements and opportunities are intersecting and how alignment is key to success.
Yvonne Maffia

Uncategorized
Article originally posted on GovDesignHub here.
Autodesk University (AU) returns to Las Vegas from November 19-21 – and we have some good news. In addition to discounted conference passes now available on GSA Schedule, Autodesk Certification exams are back at AU 2019!
Caron Beesley

Uncategorized
By Mav Turner, VP, Product Management, SolarWinds
For federal IT pros, moving to a cloud environment is a “when” rather than an “if” proposition. From the government’s recently released Report on IT Modernization, calling for agencies to identify solutions to current barriers regarding agency cloud adoption, to the White House’s draft release of a new “Cloud Smart” policy, which updates the “Cloud First” policy introduced in 2010; cloud migration continues to be a priority.
DLT Solutions

Federal Fiscal Year End, Uncategorized
The old business adage runs, “Nothing happens until somebody sells something.” To which you might add this corollary: nothing good happens in the absence of strong requirements.
Brian Strosser

Data & Storage, Infrastructure
DLT Solutions recently sat down with NetApp Senior Director of U.S. Public Sector Channel Sales, David Drahozal, to discuss the recent revolution of NetApp's data fabric solutions.
DLT: So David, tell us a little about what you do at NetApp.
David: For over a decade, I’ve had the privilege of leading the US Public Sector channel here at NetApp. Its been a real exciting time as we have evolved from a NAS company to a leader in the consolidated virtualized data center, to today being a leader in hybrid cloud capabilities.
DLT Solutions

IT Perspective, Uncategorized
The latest data on the progress of federal government agencies’ implementation of the Federal Information Technology Acquisition Reform Act (FITARA) was released on June 26 by the House Oversight and Reform Committee as Scorecard 8.0.
Melissa Perez

Cloud Computing, Uncategorized
Key takeaways show how public sector customers are achieving more with cloud.
As cloud continues to transform the public sector, cloud has had its own metamorphosis: from a trendy buzz word to a catalyst for meaningful change, innovation, and more. Last month, AWS hosted its 10th annual AWS Public Sector Summit. The conference brought together more than 17,000 attendees for 2+ days of insights, sessions, and networking, and explored how cloud is fueling the public sector for a limitless future.
Recap
Isabella Jacobovitz

Uncategorized
Many states' fiscal years are quickly coming to an end, and at DLT we’re committed to making the job of the procurement officer as easy as possible as they scramble to make smart and responsible purchasing decisions with remaining taxpayer dollars. Part of this process is raising awareness of what’s new in our extensive portfolio of IT solutions including big data and analysis, cloud, cybersecurity, application lifecycle, digital design, IT consolidation and management, and more.
Brian Strosser

Uncategorized
Earlier this year DLT announced they were selected as the “Master Government Aggregator”
DLT Solutions

Business Applications, Uncategorized
Not all Ivy League schools have massive endowments and bank accounts. Some have to get more creative when looking to build new facilities on a budget – or simply embrace innovative new approaches to design and construction.
DLT Solutions

Business Applications, Uncategorized
It’s that time of year again! Spring is here and Autodesk has commenced its steady roll-out of 2020 software releases.
First off is AutoCAD 2020. Released in late March 2019, AutoCAD 2020 includes interesting and exciting new features. With a subscription to AutoCAD 2020, you’ll get industry-specific toolsets; improved workflows across all your devices – web, mobile, and desktop; and new integrations with cloud storage vendors.
Here’s a round-up of what’s new.
Kirk Fisher

Digital Design, Uncategorized
When we launched GovDesignHub in the spring of 2018, we had one goal in mind – to address the lack of resources, discussion, and analysis available online for those who practice in government digital design ecosystem.
Today, we’re proud to be the only website that showcases government design projects and the technology used to support them and deliver content to help public sector organizations accomplish their missions.
In the words of one of our top contributors, Lynn Allen, of Autodesk fame:
Holly Chapman

Federal Fiscal Year End, Uncategorized
Congress first enacted federal appropriations law in 1809. It’s kept lawyers, contractors, and judges busy ever since. A question arising in many sellers’ minds at this time of year is, what money is available for contracts in more than one fiscal year?
Tom Temin

Data & Storage
Any federal IT pro can tell you that analyzing log files is something they’ve been doing for years. That said, as applications get more complex, performance becomes more important and security issues increase. Log analytics are fast becoming a critical component of an agency’s monitoring and management infrastructure.
Paul Parker

Data & Storage
So much data, so little time. Disparate sources such as sensors, machines, geo-location devices, social feeds, server and security system logs, and more, are generating terabytes of data at unfathomable speeds. Getting any kind of real-time insight and, we dare you to dream, acting on that data as it flows in, is not an easy feat for resource-constrained government agencies.
Rachael Hendrickson

Digital Design, Uncategorized
New York City Department of Design and Construction (NYC DDC) handles some of the most exciting and dynamic architectural and infrastructure challenges in the world.
Grace_Bergen

Digital Design, IT Perspective, News, Technology, Tips and How-Tos, Uncategorized
The CAD and digital design sector is vast and growing at breakneck speed. It’s expected to reach $11.21 billion by 2023.
Many end-use industries such as automotive, aerospace, entertainment, industrial machinery, civil and construction, electrical and electronics, pharmaceutical, and healthcare, consumer goods, and others, widely use CAD and 3D design-based tools in their development processes.
DLT Solutions

Big Data, Big Data & Analytics, Data & Storage, Data and Analytics, Healthcare, Technology
Blockchain is no longer just a buzzword or simply a “technology to watch.” This database technology is being explored by agencies across government, from the General Services Administration (GSA) to Centers for Medicare and Medicaid Services (CMS), from the Federal Maritime Commission to military supply chain professionals across the Department of Defense (DoD).
The promise of blockchain is dramatic. It can help enhance agencies’ business processes and provide far greater transparency and efficiency.
Paul Parker

CAD General, Digital Design, IT Perspective, Technology, Uncategorized
Aside from developing one of the sought after building information modeling (BIM) software in the industry today, you’ve got to hand it to the Revit product managers over at Autodesk—they listen.
Grace_Bergen

CAD General, Digital Design, Technology, Uncategorized
Whether you’re a civil engineer, CAD manager, or anyone working on a digital design project, one thing is certain – you’re never the sole collaborator in the process. Contractors, AEC firms, field personnel, even facilities managers, have their hands in the mix too. And that creates a problem for version control and the potential for incorrect information in the field. How do you know you’re working with the most current information? If you’re using traditional non-digital workflows, it’s a problem you likely encounter once too often.
DLT Solutions

Cloud Computing, Cybersecurity, Data, IT Perspective, News, Technology, Uncategorized
Another day, another government ransomware victim. On March 22nd, 2018, the city of Atlanta found itself locked out of computers across government offices and facing a ransom demand of $51,000 or $6,800 per computer, GCN reported.
DLT Solutions

Digital Design, Technology, Tips and How-Tos, Uncategorized
If you’re fairly new to Autodesk Revit and looking for ways to quickly get up to speed, Autodesk put together a great webinar that offers tips and tricks to get the most out of your user experience. Topics included:
• How does it differ from AutoCAD?
• What do I need to know to get started?
• What are some best practices for working in Revit?
• What are families and how do I use them?
• Where to learn more and how to get support when problems happen
Grace_Bergen
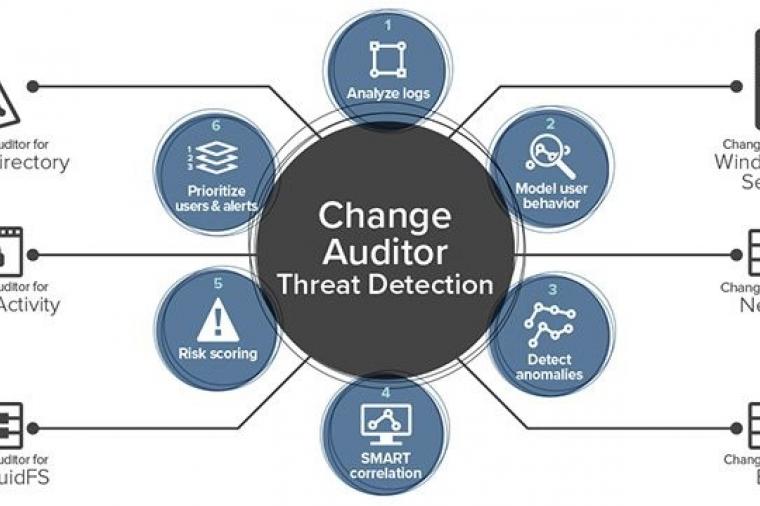
Cybersecurity, Infrastructure, Technology, Uncategorized
Microsoft Active Directory is a critical tool that helps system administrators manage user privileges and secure their IT infrastructure, yet Active Directory presents several security challenges. Most problematic is that Active Directory’s attack surface is huge. Targets for attack include every domain name user account, admin and security group, domain controller, backup, admin workstation, and admin delegations and privileges. If any one of these targets is compromised, your entire Active Directory can be compromised too.
The Threats
BradleyGernat

Cybersecurity, Infrastructure, IT Perspective, Technology, Uncategorized
Microsoft Active Directory is a critical tool that helps system administrators manage user privileges and secure their IT infrastructure, yet Active Directory presents several security challenges. Most problematic is that Active Directory’s attack surface is huge. Targets for attack include every domain name user account, admin and security group, domain controller, backup, admin workstation, and admin delegations and privileges. If any one of these targets is compromised, your entire Active Directory can be compromised too.
The Threats
BradleyGernat
Cloud Computing, Uncategorized
Are you thinking of moving your databases to the cloud? Perhaps, you’re thinking about transitioning to database-as-a-service (DBaaS)? But what’s involved? What hurdles must be overcome and how do you chart a path to cloud migration of your most sensitive workloads?
Why Move Databases to the Cloud?
Migrating to the cloud offers several benefits to public sector database administrators (DBAs).
BradleyGernat


Cloud Computing, Data & Storage
DLT has been a partner of Ansible for several years, and in 2015 when another partner of ours, Red Hat, acquired Ansible, our government customers gained new opportunity to make the automated enterprise a reality.
What is Ansible?
victoria.negron

Data & Storage
Your database is truly critical to the successful operation of your data center, yet databases pose extraordinarily complex management challenges. Try as you might to resolve issues as they arise, you may find yourself coming up short.
Part of the problem is that many people consider database health and performance to be one and the same, but that’s not necessarily the case. These concepts aren’t strictly interchangeable, and if you treat them as such, you may be impeding your own ability to troubleshoot.
DLT Solutions

Data & Storage
Want a good idea of “what’s coming next” in federal IT? Look no further than the financial services industry.
Consider the similarities between financial firms and government agencies. Both are highly regulated and striving for greater agility and efficiency and better control of their networks and data—not to mention both are highly regulated. Meanwhile, cybersecurity remains a core necessity for organizations in both industries.
DLT Solutions

News, Uncategorized
Declining Spending Begins to Bounce Back with Rising Budgets
Over the past six years, we’ve seen a decline in government spending. But recently, there was been an increase in contract spending that is predicted to continue into fiscal year 2017. According to a study by Bloomberg Government, 60 percent of government spending is consistently on services; knowledge-based services, facility-related services, and technology services. The largest product spending is on technology equipment, with aircraft spending in second.
MayaSmith
News, Uncategorized
NSA Use of Software Flaws for Hacking Posed Risk to Cybersecurity
Recently, the Nation Security Agency’s (NSA) hacking tools were leaked to the public, exposing many vulnerabilities across the internet and putting companies at risk of data breaches. Many say that the NSA should have disclosed each vulnerability as soon as they discovered it so that they could be fixed. Software vendors like Cisco, Juniper and Fortinet are actively working with their customers to ensure that any flaws in their systems are fixed immediately.
MayaSmith
News, Uncategorized
DNC Creates Cybersecurity Advisory Board Following Hack
Following the WikiLeak email dump right before the Democratic National Convention (DNC), the Democratic National Committee is creating a cybersecurity advisory board consisting of four industry experts. The board will be responsible for preventing future attacks on the DNC and making sure its cybersecurity capabilities are up-to-par. The committee will also ensure that those whose data was stolen will be protected so that further information from their accounts does not get leaked.
MayaSmith
News, Uncategorized
The Most Critical Skills Gap: Cybersecurity
Since Target’s hack back in 2013, cybersecurity has been top of mind for organizations, especially those with sensitive information. However, the talent pool of those who are skilled in intrusion detection, secure software development and attack mitigation is not growing at the same rate as the demand. Many reasons contribute to this disconnect, including a lack of training in higher education and a 53% increase in need.
MayaSmith
News, Uncategorized
Technology Is Monitoring the Urban Landscape
MayaSmith

Data & Storage
Social media has had a significant impact on federal, state, and local governments across the country. From the routine to the critical, social media has become a vital tool for building awareness of missions, sharing policy updates, communicating services and products, and enhancing citizen engagement. The immediacy of social media is also particularly useful to emergency response agencies who can leverage its outreach capabilities to aid response efforts.
AndreJones
News, Uncategorized
Posing as Ransomware, Windows Malware Just Deletes Victims’ Files
MayaSmith
Uncategorized
It's finally here!
Amazon Web Services (AWS) just announced that the Elastic File System (or "EFS") is a live production service. The service is provisioned out of three regions currently: US-EAST-1, US-WEST-2, and EU-WEST-1.
EFS was originally announced over a year ago at AWS re:Invent in 2015. By AWS standards, the service has been in "preview" for quite some time. I'll admit to you, I was getting a little skeptical that it was going to make it out of preview, but hey, it's good to be wrong sometimes.
Chris Uttenweiler

Digital Design, Uncategorized
The dog days of summer are officially here. So what better time to brush up on your digital design skills. Here are some options for getting ahead of the curve this summer.
Grace_Bergen
News, Uncategorized
Can Cybersecurity Insurance Improve Threat Management?
Following the Brussels, Belgium terrorist attacks back in March, the U.S. House Homeland Security Cybersecurity Subcommittee met to discuss cyberinsurance and how to better promote cybersecurity best practices in general. Many are still questioning whether cyberinsurance will help solve the problem of threat, but the Department of Homeland Security believes it can, by acting as an incentive for better security practices within agencies.
MayaSmith

Digital Design, Uncategorized
Reality capture technology as a means of capturing existing as-built conditions has been around for some time. Terrestrial laser scanning or LiDAR is just one example of reality capture (or recap) at work. But recap hasn’t always been easy. Scanning techniques are often expensive and the task of incorporating and manipulating large data sets (point clouds) during the design process is tricky.
AndreJones

News, Uncategorized
This All-Star Team Plans to Jumpstart 100 Cybersecurity Companies in 3 Years
MayaSmith

Cybersecurity, Uncategorized
I’m fed up. Better yet, I’m “F.U.D.-ed” up. In every cybersecurity conference, in every threat report, in every blog and every bit of cybersecurity marketing literature I see one tiresome theme: “The bad guys are after us! It’s getting worse every day! How will we fix it? Can we fix it? There’s no magic bullet! The cyber sky is falling, run for your cyber life!” In other words, an unrelenting stream of– Fear, Uncertainty, and Doubt.
Don Maclean

Digital Design, Uncategorized
There are less than six months to go until Autodesk University (AU) lights up Las Vegas November 15-17, 2016 for its annual convergence of CAD professionals looking to learn, connect and explore the best in digital design.
But what do we know about the event so far? Here’s what:
Caron Beesley

Data & Storage
Data is an incredibly important asset. Unfortunately, too many agencies continue to treat data as an easily replaced commodity.
But we’re not talking about a database administrator’s (DBA) iTunes library. We’re talking highly sensitive and important government data that can be too easily lost or compromised.
It’s time to stop treating data as a commodity and create a secure and reliable data recovery plan by following a few core strategies.
Marketing
News, Uncategorized
Why Small Bites Make Sense for Cloud
Karen Petraska, service executive for computing services at NASA, spoke at last week’s AWS Public Sector Summit about taking small bites before fully committing to the cloud. Trial contracts, for one, are an easy way to slowly introduce the cloud into your environment while still leaving room to expand and adjust accordingly. Petraska also discussed NASA’s use of “non-specific ordering,” which allows NASA employees to use a refillable card when buying cloud services.
MayaSmith

Cybersecurity, Uncategorized
Data leaks, data breaches, blah, blah, blah. Sometimes the attention-grabbing headlines just sound like too much noise.
What’s lacking in most of today’s reporting is the real truth about how government agencies are hacked and what agencies are doing to counter those attacks. Those are the details that can help agencies improve their defenses to face future challenges.
AndreJones

IT Perspective, Uncategorized
When news broke last month that the Pentagon is still using 1970s-era floppy disks to run its nuclear program, most of us expressed incredulity. Unless you happen to work for the federal government that is.
According to federal CIO Tony Scott, the U.S. government spends 76% of its $88 billion IT budget on operating and maintaining out-of-date technologies – that’s three times what is spent on modern systems.
Shayna_Williams

Data & Storage, Uncategorized
Growing data volumes and burgeoning virtual workloads are putting increasing pressure on public sector data center power and storage systems, while also taking a toll on staff and tax payer dollars.
Performance silos, forklift upgrades and increasing licensing costs are forcing organizations to change how they do business. But agencies can turn this situation around in a flash!
Shayna_Williams
Data & Storage, Uncategorized
Growing data volumes and burgeoning virtual workloads are putting increasing pressure on public sector data center power and storage systems, while also taking a toll on staff and tax payer dollars.
Performance silos, forklift upgrades and increasing licensing costs are forcing organizations to change how they do business. But agencies can turn this situation around in a flash!
Shayna_Williams

Data & Storage, Uncategorized
Data backup is a fundamental part of good IT and business management. But in the public sector it’s also the law. Established by President Obama in 2011, the National Archives and Records Administration maintains a comprehensive backup of all records of important transactions, actions, and other communications.
Although data backup sounds like a simple enough concept, the actual practice of consistently performing reliable backups and staying compliant with mandates and regulations offers up many significant challenges:
Caron Beesley